Interpreting the next generation of Ethereum Layer2 solutions: Based Rollups

Reprinted from jinse
02/05/2025·2MSource: Dengchain Community
Rollups are growing rapidly. Initially, typical rollups provided short-term solutions to Ethereum’s scalability challenges. Now, with the advancement of technology, we are building the next generation of rollups that not only further expand Ethereum, but also retain decentralization, security and economic sustainability.
In a four-part series called Interpreting the Next Generation L2, we explore some new rollup types—Based rollups, Booster rollups, gigagas rollups, native rollups—and aim to introduce these designs to a wide audience . These rollups represent the future of Ethereum expansion, and given @2077Research's commitment to making Ethereum Research and Development (R&D) accessible, we believe it is important for the education community to understand the updated L2 design.
Our goal is to quickly introduce these technologies and clarify relevant concepts. In this series, we will break down each rollup type to explore their design, strengths, tradeoffs, and overall impact on the Ethereum roadmap. Whether you are an Ethereum enthusiast, developer, or curious about blockchain scalability, this series is for you.
The first article focuses on Based Rollups – a proposed method of building rollups designed to mitigate problems with classic rollups such as sorter centralization, lifecycle risks, and censorship resistance. We will explore how Based Rollups work, the benefits they offer, and the barriers to the adoption of Based Rollups.
What is an Based rollup?
If a rollup is used to process transactions based on sorting, it is called a Based (based) rollup. Sort refers to how transactions are executed in rollup. Instead of relying on a centralized entity ("sorting") to sort transactions based on sorting, the validator set of Layer 1 (L1) chains.
Today, traditional rollups have centralized sorters, which leads to several problems. These issues include review of user transactions, the risk of single point of failure, and MEV monopoly (centralized sorters can extract MEVs from users due to private access to memory pools (maximum extracted value).
Given the issue of centralized sorting, the Ethereum community has been looking for alternatives. Importantly, such alternative sorting designs must meet a key design goal: they must be as efficient and fast as their predecessors.
Sorting-based and Based Rollups are a positive step in this direction as they provide a new way to sort transactions for rollups, inheriting Ethereum’s censorship resistance, eliminating single point of failure, and avoiding decentralization Sacrifice speed. Let's describe how Based Rollups work below.
How does Based rollups work?
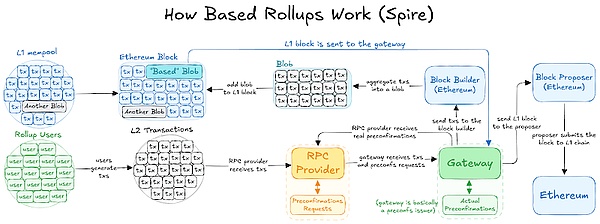 Description of the Based rollup
architecture of @Spire_Labs
Description of the Based rollup
architecture of @Spire_Labs
The main difference between a rollup based on a rollup and any other type of rollup is how transactions are sorted. In rollup-based, transaction sorting is managed by the underlying L1 blockchain (Ethereum here). Specifically, in rollup-based, “any next L1 proposal is free to include subsequent rollup blocks in the next L1 block together with the L1 finder and builder without special permissions.
In a rollup-based architecture, the user's transactions are directed to L1 builders who have agreed to be Ethereum and L2-based building blocks. The user indicates its maximum transaction fee, L2 captures the underlying fee (set according to the L2 network congestion situation) and forwards the priority fee (paid to the prompts contained in the incentive transaction) to the validator, which determines the order of the transaction.
This arrangement allows Ethereum not only to ensure all fees for its ecosystem, but also to charge a portion of the L2 prompt, as well as the transaction settlement fee. Returning value to L1 makes Based Rollups symbiotic relationship with Ethereum and eliminates the idea that rollups are parasitics in Ethereum. Another benefit of sorting L2 transactions with L1 proposers is that it eliminates the intermediary steps in the transaction process. This can potentially lead to lower transaction costs by avoiding the need to verify signatures from centralized or decentralized sorters.
It is worth mentioning that this cost reduction is not unique to Based Rollups; any rollup that uses shared sorting may see similar benefits. Since the proposed blocks on L1 are permissionless, this promotes a competitive environment among block builders, which may further reduce user fees.

Description of taiko Based rollup architecture
Since its proof is submitted directly to Ethereum based on rollup, its settlement is essentially on Ethereum. This means that anyone can access the verified state of the L2 chain on Ethereum. Based on rollup, settlement cannot be performed outside its underlying L1.
Release the data needed to rebuild its chain state on Ethereum based on rollup, making Ethereum its data availability (DA) layer. This allows anyone to verify the block hash and retrieve transaction data from the block. Based Rollups uses Ethereum's consensus layer to sort transactions, thereby eliminating the need for its own consensus mechanism.
Transaction execution in rollups takes place off-chain within its ecosystem, which means based on rollup itself as its own execution layer. For example, existing Based Rollups, such as taiko and SpireLabs, while checking on Ethereum, run on the same L1, but maintain their own unique execution layer to execute transactions.
What are the advantages and disadvantages of rollup-based design?
Advantages of Based Rollups include inheriting Ethereum's security and activity, potentially reducing transaction costs by eliminating additional sorting, allowing L2 transactions to interact with L1 states, simplifying the architecture without separate consensus, ensuring that all data is in Data availability on Ethereum, as well as providing strong censorship resistance.
However, like everything in encryption, design-based concerns are also found. Based Rollups relies on Ethereum's performance, which may limit scalability due to Ethereum's block space limitations. L2 operations are still related to gas costs, which may be considerable. There is also the problem with MEV, that is, L1 validators may affect transaction sorting. The close association with Ethereum consensus and data layer may limit customization of specific use cases.
Based Rollups FAQ
In this section, we answer some frequently asked questions about Based Rollups. Our goal is to remove specific misunderstandings about Based Rollups and provide clear information on all aspects of the rollup-based architecture.
How to manage MEV based on rollup?
Most MEVs benefit L1 validators because the motivation for L1 finders and block builders is to include rollup blocks in their L1 packages for this value, thereby encouraging L1 proposers to include these blocks. Currently, about 80% of Ethereum MEVs come from congestion and 20% come from competition. If the L2 MEV reflects this, a large portion may remain in L2.
Is using rollup based on it cheaper for users compared to alternatives?
Using the L1 proposer as an L2 sorter can eliminate an intermediary step, potentially reducing costs by eliminating the sorter signature verification. This cost-saving approach is not only for rollup-based, but also for shared sorted rollups, as permissionless block proposals promote competition and may reduce costs.
Is rollup-based speed limited to Ethereum's block time?
Yes, the rollup-based transaction confirmation time is related to the block time of L1, currently 12 seconds. However, instant pre-confirmation can be achieved based on rollup. This can be achieved through a mechanism like restaking, where some L1 validators promise to include rollup-based blocks in their future L1 blocks. This is possible because the validator can know 32 blocks in advance who will propose each block.
How "real-time" is rollup-based activity?
Based on the activity guarantee of sorting and sharing Ethereum, it fully inherits its uptime. Even a slight decrease in activity (e.g., from 100% to 99%) can be exploited under confrontational conditions, resulting in significant disturbance and toxic MEV.
What is the difference between sorting based and shared sorting?
Sort based can be considered a specialized version of shared sorting. Shared sorting is a transaction sorting system across multiple rollups, aiming to achieve economic efficiency, higher throughput, and faster confirmation than L1. What makes it different from rollup-based is that it uses its own operator to agree on, making it more complex and does not rely entirely on Ethereum's activity.
in conclusion
In the first article in our “Rollups 2.0” series, we explore rollup based on it, which leverages Ethereum validators for transaction sorting, providing a path to decentralization, security, and cost efficiency.
As we continue this series, we will dive into enhanced rollups, native rollups and hyperscale rollups—to examine how these types of rollups solve different aspects of Ethereum’s scalability.

 panewslab
panewslab